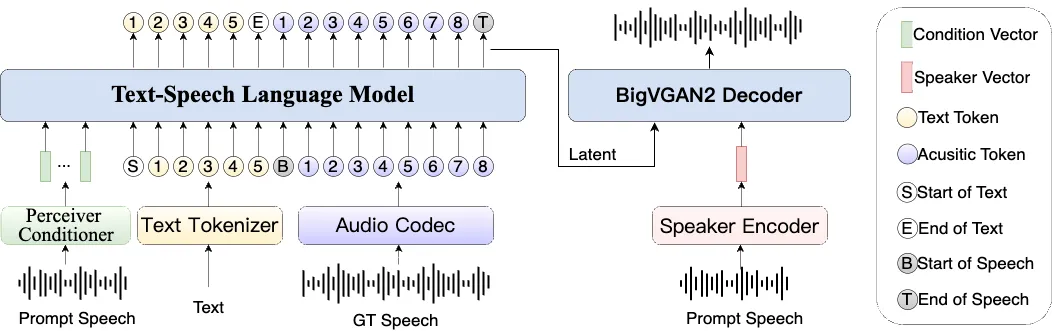
MOSS-TTSD
综合介绍
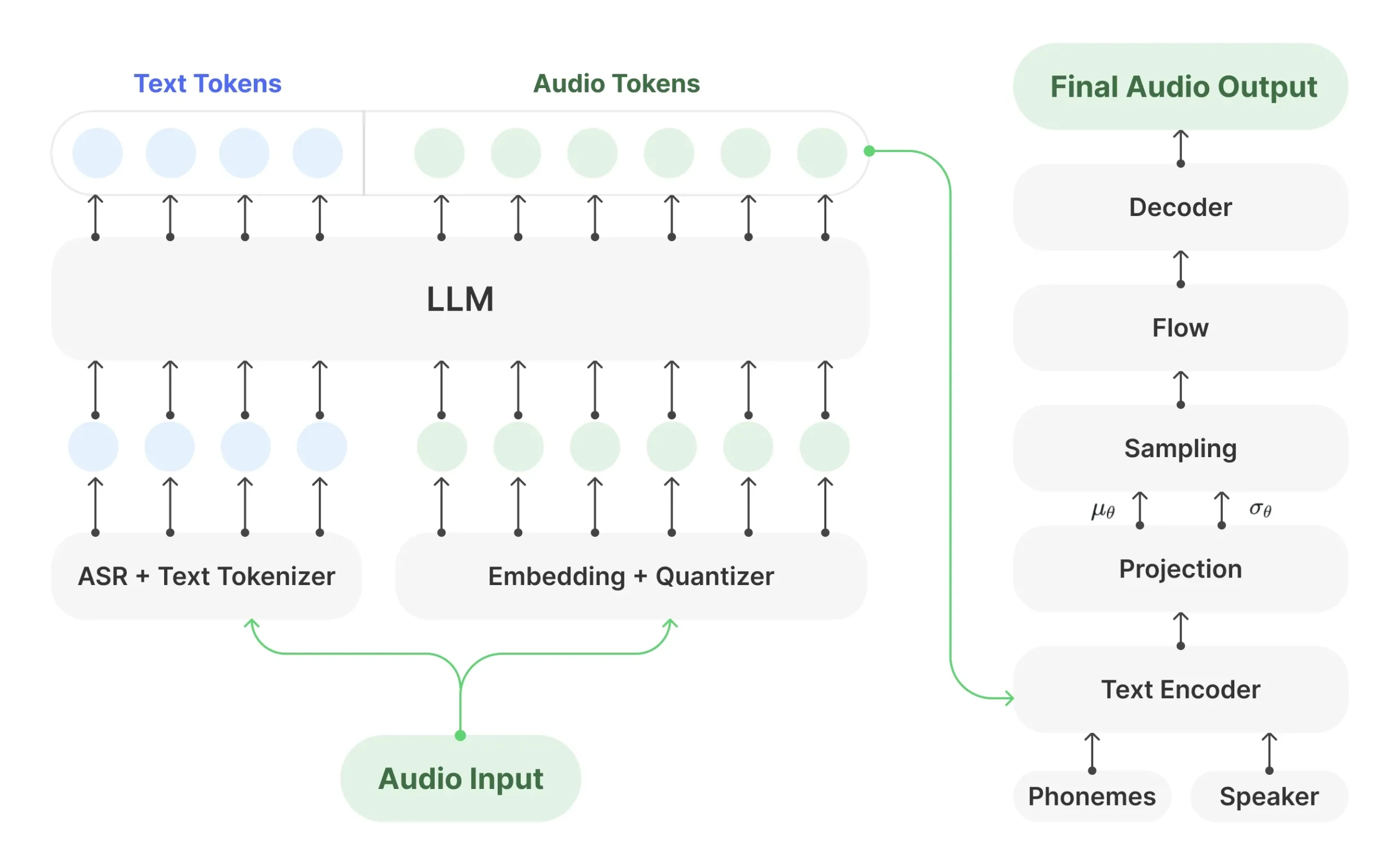
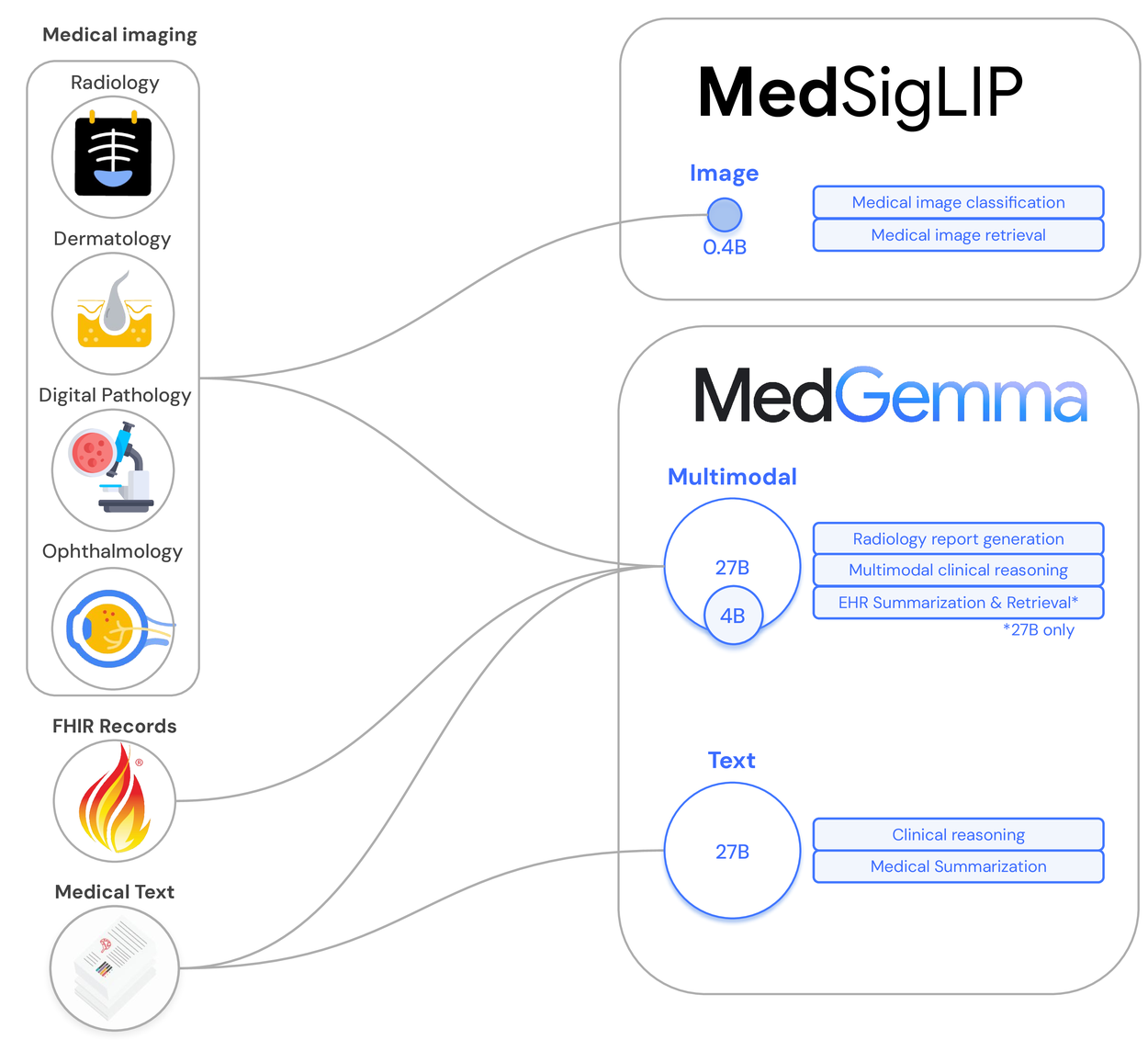
MOSS-TTSD 是一个开源的双语(中文和英文)对话式语音生成模型。它可以将包含两个说话者的对话文本,转换成带有自然情感和语气的语音。这个模型的核心功能是零样本(zero-shot)多说话人声音克隆,意味着不需要提前训练特定人物的声音,就可以模仿任何人的音色来生成对话。MOSS-TTSD 还能生成较长的语音,很适合用来制作AI播客等内容。该项目基于一个统一的语义声学神经音频编解码器和预训练的大语言模型,并使用了大量的语音数据进行训练,因此生成的语音在表达力和自然度上表现出色。项目本身是完全开源的,并且允许免费用于商业目的。
功能列表
- 高表现力对话语音:基于海量语音数据训练,可以生成带有自然对话韵律、接近真人说话风格的语音。
- 双人声音克隆:支持零样本(zero-shot)克隆两个不同说话者的声音,并能根据对话脚本准确切换。
- 中英双语支持:能够生成流畅且富于表现力的中文和英文语音。
- 长音频生成:经过优化,支持生成单次较长的语音内容,适合播客等场景。
- 开源与商用:项目完全开源,并使用 Apache-2.0 许可,允许免费的商业使用。
- 播客生成工具:提供一个名为
Podever的播客生成流程,能自动将网址、PDF或长文本文件转换成高质量播客。 - 模型微调:提供完整的微调脚本和工作流,用户可以使用自己的数据对模型进行微调,以适应特定需求。
使用帮助
MOSS-TTSD 提供了多种使用方式,包括本地推理、Web界面、API调用以及模型微调。以下是详细的操作流程。
环境安装
首先,你需要创建一个合适的Python环境并安装所需的依赖包。推荐使用conda进行环境管理。
- 创建并激活Conda环境:
conda create -n moss_ttsd python=3.10 -y conda activate moss_ttsd - 安装依赖包:
pip install -r requirements.txt pip install flash-attn - 下载XY Tokenizer模型:MOSS-TTSD的运行需要依赖XY Tokenizer模型,需要手动下载。
mkdir -p XY_Tokenizer/weights huggingface-cli download fnlp/XY_Tokenizer_TTSD_V0 xy_tokenizer.ckpt --local-dir ./XY_Tokenizer/weights/
本地推理
本地推理是最直接的使用方式,通过命令行运行脚本,输入一个JSONL格式的文件,即可生成语音。
- 准备输入文件:输入文件必须是
.jsonl格式,每行一个JSON对象。支持以下几种格式:- 格式1:纯文本输入(不使用声音克隆)
{ "text": "[S1]说话人1的对话内容。[S2]说话人2的对话内容。[S1]..." } - 格式2:为两个说话人分别提供参考音频
{ "base_path": "/path/to/audio/files", "text": "[S1]说话人1的对话内容。[S2]说话人2的对话内容。", "prompt_audio_speaker1": "speaker1_audio.wav", "prompt_text_speaker1": "说话人1参考音频对应的文本", "prompt_audio_speaker2": "speaker2_audio.wav", "prompt_text_speaker2": "说话人2参考音频对应的文本" } - 格式3:提供一个包含两种声音的混合参考音频
{ "base_path": "/path/to/audio/files", "text": "[S1]说话人1的对话内容。[S2]说话人2的对话内容。", "prompt_audio": "shared_reference_audio.wav", "prompt_text": "[S1]说话人1的参考文本。[S2]说话人2的参考文本。" }
注意:文本中的
[S1]和[S2]是固定的说话人标记,用于区分和切换角色。 - 格式1:纯文本输入(不使用声音克隆)
- 运行推理脚本:使用
inference.py脚本来生成语音。python inference.py --jsonl examples/examples.jsonl --output_dir outputs --seed 42 --use_normalize--jsonl: 指定输入文件的路径。--output_dir: 指定生成音频的保存目录。--seed: 随机种子,用于保证结果可复现。--use_normalize: 建议开启,用于对输入文本进行归一化处理。
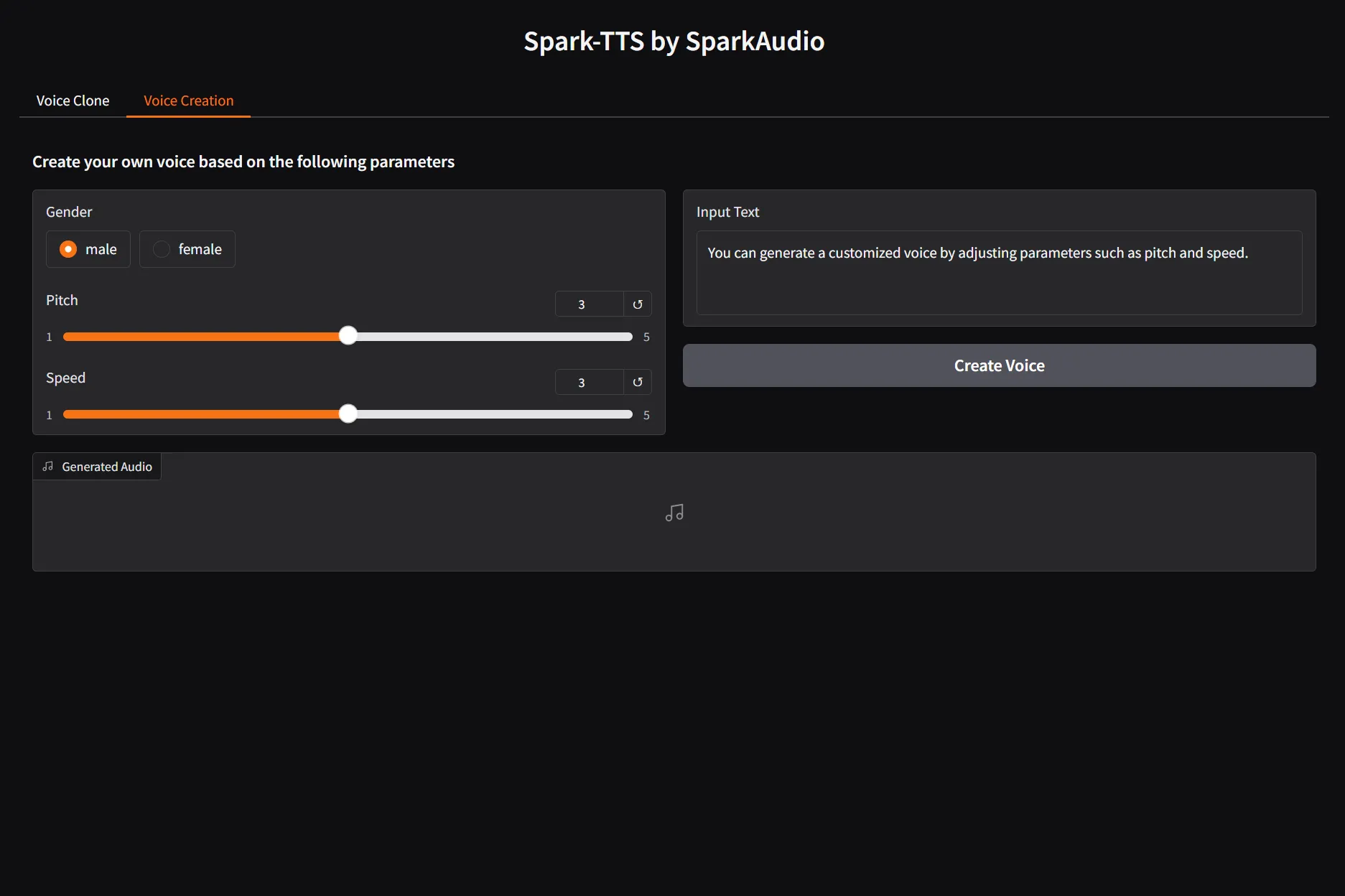
Web UI 使用
如果你更喜欢图形化界面,可以运行Gradio搭建的Web Demo。
- 启动Web服务:
python gradio_demo.py - 操作界面:启动后,在浏览器中打开对应的本地地址。你可以在界面上输入文本、上传参考音频,然后点击生成按钮来获得语音。
播客生成
该项目提供了一个非常实用的工具,可以直接将一篇文章或一个PDF文件转换成双人对话形式的播客。
- 设置API密钥:该功能需要使用 Gemini API 来生成对话脚本,因此需要先设置好环境变量。
export OPENAI_API_KEY="your_gemini_api_key" export OPENAI_API_BASE="https://generativelanguage.googleapis.com/v1beta/openai/" - 运行生成脚本:
- 处理网页文章:
python podcast_generate.py "https://www.open-moss.com/cn/moss-ttsd/" - 处理PDF文件:
python podcast_generate.py "examples/Attention Is All You Need.pdf" - 处理本地文本文件:
python podcast_generate.py "examples/example.txt" - 指定输出语言(默认为中文
zh):python podcast_generate.py "your_input" -l en
- 处理网页文章:
模型微调
对于有特定需求的高级用户,可以利用项目提供的脚本在自己的数据集上对模型进行微调。
- 准备微调环境:微调需要的依赖包与推理不同,需要单独安装。
pip install -r finetune/requirements_finetune.txt pip install flash-attn - 准备数据:按照本地推理中描述的JSONL格式,准备你的训练数据。为了避免路径问题,强烈建议在JSONL文件中使用绝对路径。
- 一键式微调工作流:项目提供了一个
finetune_workflow.py脚本,可以自动化完成数据预处理和模型训练两个步骤。- 配置工作流:首先,复制
finetune/finetune_config.yaml模板文件,并根据你的实际情况填写参数,如数据路径、模型输出路径等。path_to_jsonl: /path/to/your/training_data.jsonl data_output_directory: /path/to/processed_data data_name: my_dataset use_normalize: true finetuned_model_output: /path/to/output/fine_tuned_model use_lora: true # 是否使用LoRA微调 - 运行工作流:
python finetune/finetune_workflow.py --config path/to/your/config.yaml
微调支持全量微调和LoRA微调两种方式。LoRA(低秩自适应)是一种参数高效的微调方法,能够在消耗更少计算资源的情况下取得良好效果,适合个人用户或算力有限的场景。
- 配置工作流:首先,复制
应用场景
- AI播客制作利用其长音频生成和双人对话模拟功能,可以快速将书面内容(如新闻、博客、研究报告)转换为自然流畅的双人播客节目,极大地降低了内容创作的门槛。
- 有声书与故事叙述通过声音克隆功能,可以为有声书中的不同角色赋予独特的音色,或者让特定的声音(如作者本人)来朗读整个故事,提升听众的沉浸感。
- 个性化虚拟助手开发者可以利用该模型为虚拟助手或数字人赋予更具表现力和个性化的声音,让用户交互体验不再是单调的机器音,而是更富情感的对话。
- 语言学习与教育可以生成标准发音的中英文对话场景,帮助语言学习者进行听力理解和跟读练习。教师也可以用它来创建定制化的教学内容。
QA
- 这个模型对硬件有什么要求?模型对显存(VRAM)的要求不高。在默认的
bf16精度下,生成600秒(10分钟)的音频大约需要消耗不到7GB的显存,大部分消费级GPU都可以满足要求。 - 什么是“零样本”(zero-shot)声音克隆?零样本意味着模型不需要为了模仿某个特定的声音而进行重新训练或微调。你只需要提供一小段目标声音的音频片段(通常几秒到几十秒即可),模型就能直接生成具有该音色特点的语音。
- 模型生成的语音稳定性如何?根据官方文档,当前版本的模型在稳定性方面仍有不足,例如偶尔会出现说话人切换错误或音色克隆不准确的问题。开发团队表示会在后续版本中持续优化模型的稳定性。
- 可以将这个模型用于商业产品吗?可以。MOSS-TTSD项目使用Apache 2.0许可证,该许可证允许用户免费地进行商业使用和二次分发,但使用者需要遵守许可协议中的相关条款。